Solution Overview
In this section, we will go through each step involved in whole process from deploying the changes to production to pushing everything on git. The figure below gives a high level overview of each step.
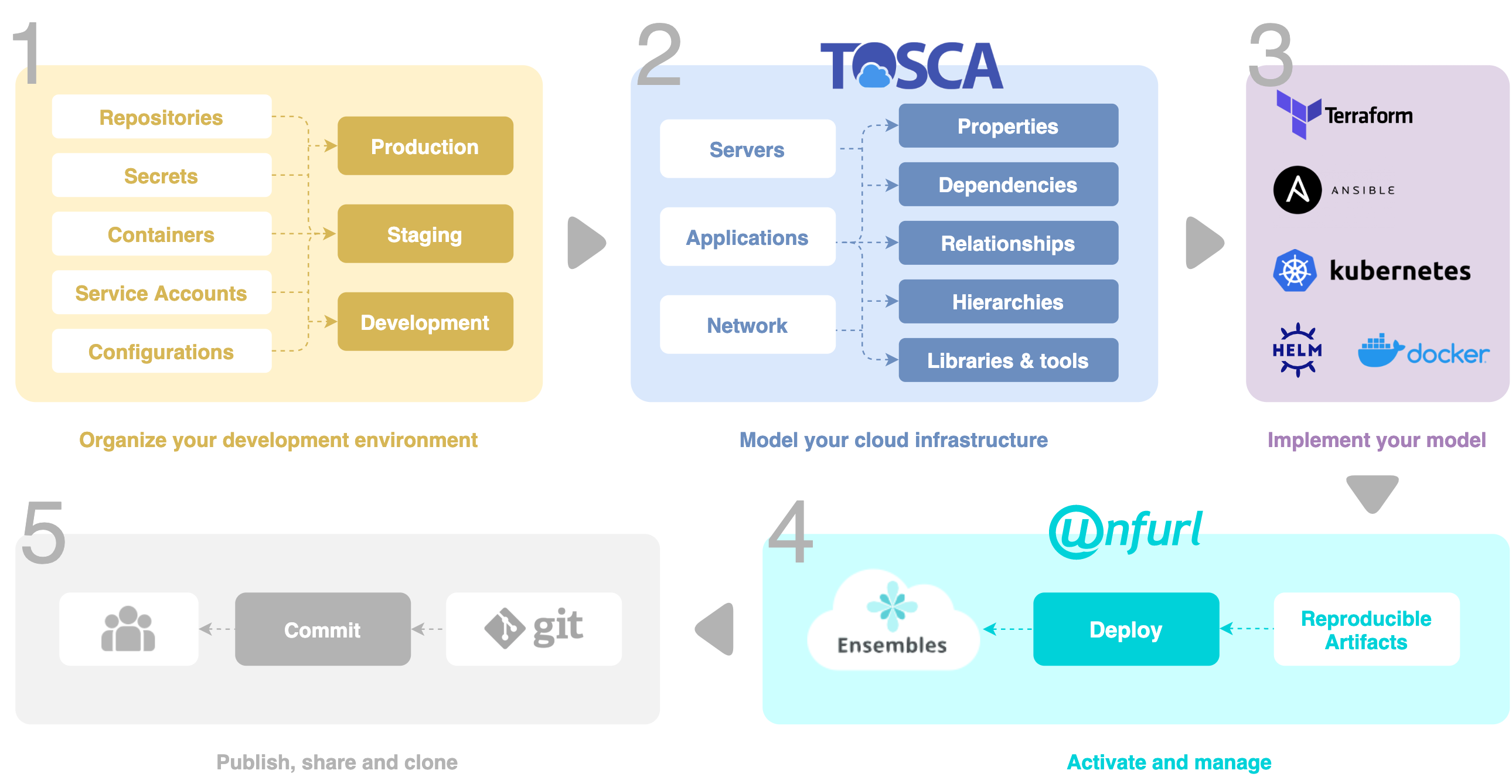
Solution overview
Step 1: Create an Unfurl Project
At the center of Unfurl are Unfurl projects. They provide an easy way to track and organize all that goes into deploying an application, including configuration, secrets, and artifacts – and record them in git. The goal is to provide isolation and reproducibility while maintaining human-scale, application-centric view of your resources.
Unfurl projects are self-contained – a project is just a collection of files in a directory. The main components of an Unfurl project are blueprints, environments, and ensembles (deployments):
Blueprints are the models described in the next step, ensembles are described in Step 4: Deploy and Manage. Environments are used to create isolated contexts that deployment process runs in. For example, you might create different context for different projects or different deployment environments such as production or staging.
Some of supported configuration including:
Cloud provider and other services’ account settings and credentials.
environment variables
secrets which can be managed in a variety of ways including support for secret managers such as Hashicorp Vault or Amazon Secret Manager or transparently encrypting them using Ansible Vault.
Mark values and files as sensitive so they can be treated as secrets.
pointers to external ensembles, providing a principled way to connect deployed services and applications.
All of these settings are exposed as TOSCA objects, providing type safety.
As you use Unfurl to deploy applications, it updates the project:
Manage one or more local git repositories to store configuration and deployment history.
Automatically install dependencies such as packages and executables and track the exact version used.
Track and manages external git repositories needed for development and deployment (e.g. automatically clone remote repositories).
.unfurl_home
Unfurl stores the local contexts such as environment variables in an .unfurl_home ensemble that represents its local environment. So you can use all Unfurl functionality to bootstrap your deployment environment and manage the local machine it is running on.
When an unfurl_home exists, other Unfurl projects will inherit the project settings defined there.
Unfurl Runtimes
Unfurl home and other Unfurl projects can include a Unfurl execution runtime which is an isolated execution environment that Unfurl can run in. This can be a Python virtual environment or a Docker container. Unfurl cli commands that executes jobs (such as unfurl deploy or unfurl plan) will proxy that command to the runtime and execute it there.
See also
Read more To setup your environment, refer to the Configure your home environment section.
Step 2: Create a Cloud Blueprint
The next step after creating a project is to create a blueprint that describe your application’s architecture in terms its resources it consumes (e.g. compute instances), the services it requires (e.g. a database) and the artifacts it consists of (e.g. a Docker container image or a software package).
These components can be declared in YAML or Python using OASIS’s Topology and Orchestration Specification for Cloud Applications (TOSCA) standard. TOSCA is a simple, declarative, object-oriented language for specifying a graph (a “topology”) of resources. Resources are specified with “node templates” that defined the properties, requirements, and operations needed to instantiate and manage the resource.
These can be declared directly on a template or by defining reusable types. So, depending on your needs, you can use TOSCA to provide ad-hoc, simple encapsulation of configuration files. Or you can use it to define a graph of strongly-typed nodes and relationships with a type hierarchy to enable reusable, cloud-provider agnostic models.
TOSCA is an abstract model: it doesn’t specify what a node template or resource might correspond to in the real world. But the TOSCA 1.3 specification does define an optional set of abstract types for common resources and Unfurl extends those with its own built-in types. In addition, the Unfurl Cloud Standard TOSCA library provides concrete types with implementations for common cloud providers like AWS and Kubernetes clusters. And you don’t need to build a blueprint from scratch – you can start with one of our project templates or fork an existing blueprint.
By using our Python DSL we can leverage Python’s IDE and tooling integrations and give you access to the same tools you have available to you when working with a modern programming language and development environment – for example, for code completion and navigation or unit testing.
Step 3: Instantiate your Blueprint

Now that we created a project with an environment and a blueprint, we are ready to translate the abstract blueprint into a concrete plan with enough detail so that it can be deployed in the targeted environment.
TOSCA lets you define CRUD (Create/Update/Delete) operations that are associated with resource definitions. Then a TOSCA orchestrator, such as Unfurl, builds a plan that selects operations for your target environment (e.g your cloud provider, or Kubernetes).
These operations may already be defined if you are using types from a predefined TOSCA library – for example the Unfurl Cloud Standard TOSCA library provides implementations for common cloud providers – but if you’ve defined your own, you’ll have to implement these yourself.
Operation can implemented as templatized Terraform modules, Ansible playbooks, or Python or Shell scripts. Or Unfurl can be taught to understand domain-specific configuration files using Unfurl’s configurator plugin system – built-in configurators include Docker, Kubernetes, Helm and Supervisor.
You can customize the blueprint’s resource templates per environment with a Deployment blueprint. A deployment blueprint extends your blueprint with templates that are only applied when they match the deployment environment.
When you’re ready to deploy, you can preview the deployment plan by running unfurl plan, which will output the plan and output (“render”) any configuration files and scripts that will be used for deployment in directory structure.
Step 4: Deploy and Manage
Now we’re ready to deploy the ensemble.
During the deploy stage, a task is run for each operation in the plan, instantiating resources as needed. When an task finishes, a Config Change record is created that records the changes to resources by made by the operation as well as the attributes it accessed. Tracking these dependencies enables efficient updates as the model changes. For more details, see Job Lifecycle.
After deployment, Unfurl records in git all the info you need for a reproducible deployment: the configuration, the artifacts used in deployment, their versions and code dependencies, and deploy, records history, as well the state of the deployment resources. This enables intelligent updates as your dependencies or environment changes.
The ensemble and change log is updated with the status and state of each resource affected. Learn more about Jobs and Workflows.
Updating your deployment
After the initial deployment, subsequent deployment plans take into account the current state of its resources.
will add, delete, or update resources if the blueprint definition changed.
will reconfigure resources if changes to their dependencies impact configuration values.
Will attempt to repair if they were left in a bad state
You can manually force and filter
Unfurl teardown will destroy deployed resources.
Resource Discovery
You can create an ensemble from existing resources instead of deploying new ones using the discover command. You can do this for entire blueprint or individual resources:
Use the unfurl discover command to discover an entire blueprint
Individual resources will be discovered instead of created when deploying a blueprint by setting the
discover node directive.Pre-defined resources (as part of the “spec”). Use the unfurl check command to check that those resources actually exist.
See Resource Discovery and Checking resources for more info.
Day-two Operations
Unfurl supports day two operations such as backups, repairs and upgrades: - It is easy to define your own workflows, interfaces and operations. - You can also execute ad-hoc operations that will be recorded in git (see Ad-hoc Jobs) You can define your own interfaces and operations.
Step 5: Share and Collaborate

Cloud services don’t exist in isolation and neither do developers. Unfurl makes it easy to share and connect blueprints and ensembles while managing integration and dependencies.
And the design of Unfurl enables open, collaborative processes built around familiar git workflows and package manager concepts.
Collaborative Development
Unfurl stores everything in git as human readable and editable source code so you can use your favorite developer tools and workflows such as pull requests. For example, using the Python DSL allows you to use popular testing frameworks like pytest. And when modifying YAML files like ensemble.yaml, Unfurl preserves comments and formatting.
Unfurl commands for managing Unfurl projects are modeled after git’s but works with multiple git repositories in tandem and includes Unfurl-specific logic such as handling encrypted content. For example, unfurl clone can clone an Unfurl project or clone blueprints and ensembles into an existing project.
You can host an unfurl project on any git hosting service like Github or Gitlab; setup is no different than hosting a code repository – See Publish your project. Or you can use Unfurl Cloud, our open-source deployment platform.
Collaborative Operations
Managing a live, production deployment collaboratively has different challenges than collaborative development. For example, uptime and access control for specific resources is more important and errors have greater consequences.
Unfurl goes beyond configuration-as-code by also recording resources’ state and status as human-readable text in git. This enables operations to be managed in much the similar development process – pull requests, reviews and approvals, CI pipelines – simplifying and accelerating development.
All the management features described in the previous step work in collaborative as they commit to git and designed for merging and review.
Some other features designed for collaborative operations:
Use remote locking to synchronize changes to resources.
clone and deploy ensembles in different environments to replicate deployments for testing and development thanks to the lock section.
Unfurl can generate unique but semantically readable identifiers and use them as cloud provider tags and labels when creating resources. These can resolve to a particular ensemble and changeset, providing clarity and easing diagnostics.
Use application-centric management UI local or on unfurl cloud – all stored in git.
unfurl cloud – access control, secrets, scheduled operations
Large-scale Collaboration
As the complexity of your cloud application increases you’ll want to move beyond monolithic deployments to components and services that can be developed and deployed independently. Unfurl provides several facilities that encourage and support the composability and integration of services. Here’s how you can use Unfurl to implement common strategies for building complex, maintainable systems:
Encapsulation and Composition. You maintain separate ensembles and blueprints for encapsulation and rely on various facilities for integrating them: import resources from External ensembles, import TOSCA libraries across repositories with isolation through TOSCA namespaces and global type identifiers, and embed blueprints inside other blueprints using substitution mappings.
Loosely-coupled Components. TOSCA has features such as node filters that allows to the selection and integration of resource templates in a dynamic, loosely-coupled way – so you can avoid hard-coding connections between components. Unfurl’s Python DSL allows you to express these constraints as simple generic Python.
Dependency Injection / Inversion of Control (DI/IoC). Ensembles can use several mechanisms that support this design pattern: the environment provides configuration including deployment blueprints to replace templates; substitution mappings can override embedded blueprints; the select node directive defines injection points.
Modular architectures such as microservices or service-oriented architectures: The Unfurl Cloud Standard TOSCA library provides high-level abstractions for services, making it easier to integrate blueprints that use them.
Semantic versioning: Unfurl tracks the upstream repositories that contain the TOSCA templates, artifacts, and code used during deployment and can apply semantic versioning to detecting conflicts and potentially breaking changes – see Repositories and Packages.
Component catalogs and repository management. Unfurl can generate a Cloud Maps of repositories, blueprints and artifacts. You can use it as a catalog for cloning blueprints and for synchronizing multiple repositories and projects. Unfurl and Unfurl Cloud’s user interfaces uses it to find compatible types and applications when building blueprints and deployments.